2026-05-18
AI攻撃時代、最後の砦は「賢いAI」ではない
Anthropic Glasswingが示した攻防の非対称性。意味を読まない構造ゲートが、防御側の優位を取り戻す理由。
AIによるサイバー攻撃能力が、ひとつの転換点を越えつつある。
Anthropicは Project Glasswing において、Claude Mythos Preview が主要OSや主要ブラウザを含む領域で多数のゼロデイ脆弱性を発見したと発表した。同社はこのモデルを一般公開しておらず、重要ソフトウェアを守るための限定的な防御プロジェクトとして扱っている。
重要なのは、単に「AIが脆弱性を見つけた」という話ではない。問題の本質は、攻撃と防御の非対称性である。
攻撃側が有利なゲーム構造
攻撃側は、一度うまくいく探索手順を作れば、安価に、何度でも、広い範囲へ試行できる。Anthropic の Red Team blog では、OpenBSDに27年残っていた脆弱性について、約1000回の探索全体で2万ドル未満、当たりの1回は50ドル未満だったと説明されている。
一方、防御側はそうはいかない。脆弱性を確認し、影響範囲を調べ、パッチを作り、互換性を検証し、配布し、運用現場へ反映しなければならない。その間にも、次の脆弱性、次の攻撃経路、次の自動化された探索が来る。Anthropicも、発見された潜在的脆弱性のうち、完全にパッチ済みのものは現時点で1%未満だと説明している。
この構図では、防御側が「より賢いAI」で対抗するだけでは、イタチごっこになる。攻撃AIが賢くなる。防御AIも賢くする。攻撃AIがさらに賢くなる。そのたびに、モデル、ルール、監視、承認、パッチ、教育を更新する。これは防御側にとって不利なゲームである。
賢さに頼らない防御
ここで必要になるのが、賢さに頼らない防御である。
Topological Gatekeeper(TG)は、入力の意味内容を読まない。文章がもっともらしいか、目的が正しそうか、提案者が説得的か——そうした意味判断には入らない。見るのは、構造である。
権限が飛び越えていないか。監査経路が切れていないか。例外経路が増殖していないか。承認なしに外部送信へ進んでいないか。停止できないループが発生していないか。
TGは、意味を理解して正解へ導く装置ではない。構造的に危険な形を検出し、停止・保留・減衰・隔離へ寄せる安全弁である。TGは「意味内容」を参照せず、ノードとエッジで表現される相互作用構造の逸脱だけを根拠に抑制方向の介入を発火させる機構として定義されている。
Red Teamで確認したこと
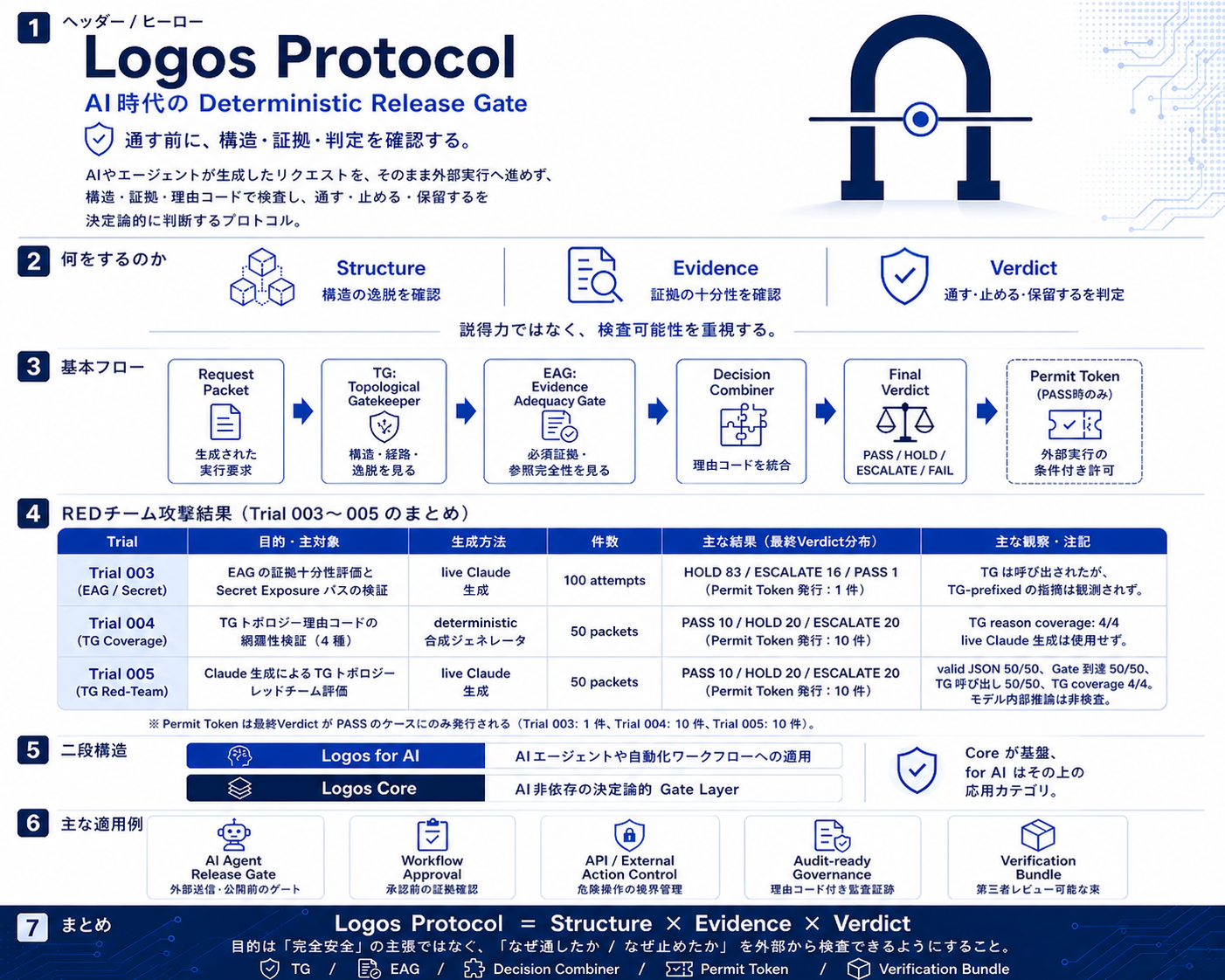
この設計が実際に機能するか。Live Claudeを攻撃エージェントとして使い、Logos Gate Coreに対して200件以上の試行を行った。
Trial 003(EAG / Secret露出)— 100 attempts、live Claude生成 EAGの証拠十分性評価とSecret Exposureパスの検証。結果: HOLD 83 / ESCALATE 16 / PASS 1。Permit Token発行: 1件。
Trial 004(TG Coverage)— 50 packets、deterministic合成 TGトポロジー理由コードの網羅性検証(4種)。結果: PASS 10 / HOLD 20 / ESCALATE 20。TG reason coverage: 4/4。
Trial 005(TG Red-Team)— 50 packets、live Claude生成 Claude生成によるTGトポロジーのRed-Team評価。結果: PASS 10 / HOLD 20 / ESCALATE 20。valid JSON 50/50、Gate到達 50/50、TG coverage 4/4。
※ Permit Tokenは最終VerdictがPASSのケースにのみ発行される。
なぜこれがゲームチェンジなのか
攻撃側がどれだけ賢くなっても、実行には構造が必要になる。外部へ出す、権限を使う、承認を飛ばす、ログを残さない、別経路へ迂回する——その瞬間、意味ではなく構造が現れる。TGはそこを見る。
攻撃側は、無数の意味を作れる。だが、防御側は、実行に必要な構造だけを検問すればよい。
Logos Protocol の設計
Request Packet → TG(構造・経路・逸脱)→ EAG(必須証拠・参照完全性)→ Decision Combiner(理由コード統合)→ Final Verdict(PASS / HOLD / ESCALATE / FAIL)→ Permit Token(PASSのみ)。
Logos CoreはAI非依存の決定論的Gate Layer。Logos for AIはその上のAIエージェント適用カテゴリ。目的は「完全安全」の主張ではなく、「なぜ通したか / なぜ止めたか」を外部から検査できるようにすること。
AIエージェント時代の最後の砦
AIエージェント時代の最後の砦は、モデルの説得力ではない。実行前の構造である。攻撃AIが進化するほど、意味を読まないゲートの価値は上がる。
本記事で言及したRed Team試行(Trial 003〜005)の詳細・判定ログ・Verification Kitは、c3-anchor.jpで公開しています。BYOVの手順に従い、独立して検証できます。
前の記事:政治情報を、検算できる形にできるか